November 5, 2025 · Zifeng Wang, PhD, Keiji AI
Predicting whether a clinical trial will succeed sounds like science fiction. Imagine knowing ahead of time whether a study will fail to reach its endpoint: like having a "what-if" medicine that lets you redo your design before the real one even begins. Tempting, right? People have been chasing this idea for years. But it's not alchemy. It's machine learning, finding patterns in the successes and failures of past trials to forecast the future ones.
Defining Success: The HINT Model
First, let's pin down what we mean by "trial outcome." In our first study, HINT [1], we defined it in a concrete way: a trial is successful if the drug it tests ultimately gains regulatory approval. That simple definition allowed us to label more than ten thousand trials, spanning phases I to III. HINT used a hierarchical model that combines drug, disease, and design features to predict whether a trial's design has the ingredients for success.
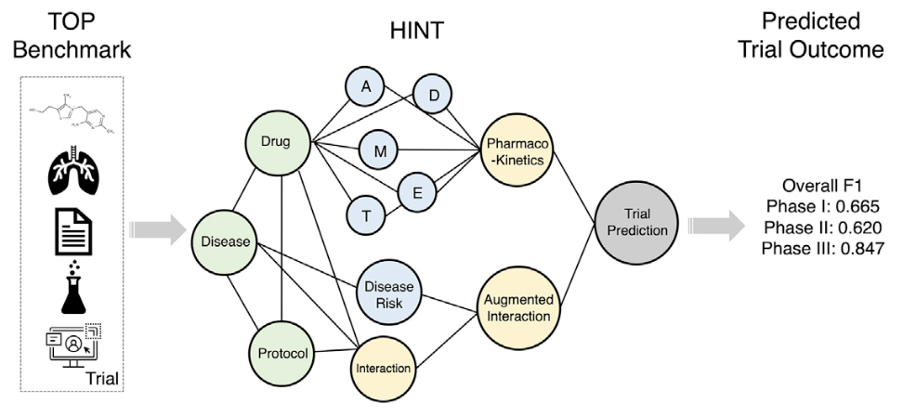
You can think of HINT as looking at a snapshot: given a trial, it judges whether the setup looks promising or flawed. But trials don't exist in isolation. A trial's fate often depends on what else is happening around it. Imagine a cancer drug aiming to cut mortality by 20%. Sounds great, until a competitor reports 40%. Suddenly your trial may be terminated early or lose regulatory traction.
Dynamic Evolution: The SPOT Model
That is exactly what we tackled next with SPOT [2]. SPOT models trials not as static points, but as evolving stories. It groups similar trials into "topics", say, all the PD-1 inhibitors for lung cancer, and learns from how those trials have evolved over time. It treats each topic as a sequence, capturing how design choices and outcomes progress from one generation to the next. Under the hood, SPOT uses sequential learning and meta-learning, letting it adapt quickly to new trial patterns even when data are sparse. The result: up to 21.5% better prediction accuracy in early-phase trials. More importantly, the model starts to reason like an experienced clinician-scientist, not just guessing, but recognizing when the "game has changed."
Building the Foundation: CTO and TrialPanorama
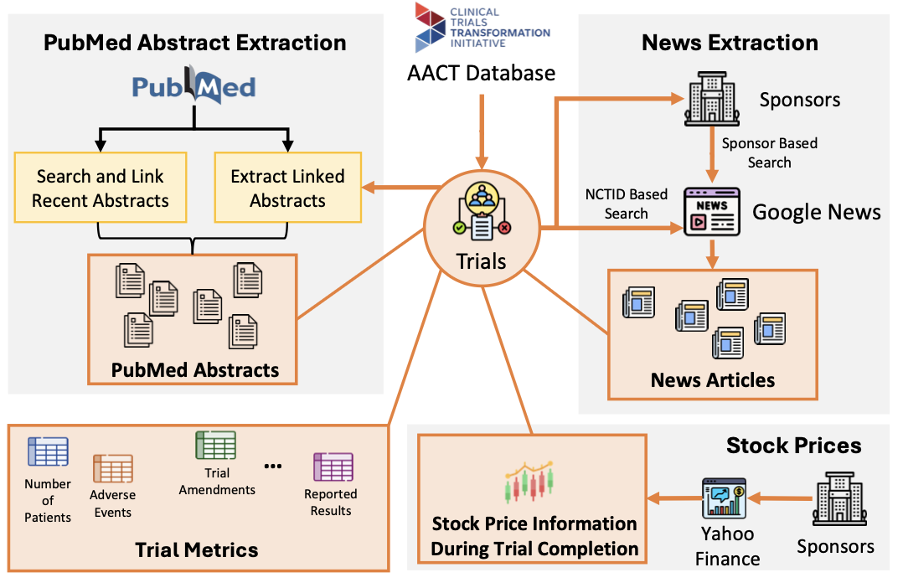
Now, algorithms are only half the story. In AI, data are often the real bottleneck. The rise of large language models has reminded everyone of a simple truth: scale and quality of data matter more than any clever model tweak. That's why we built CTO, short for Clinical Trial Outcome labeling [3]. CTO uses LLMs to automatically extract structured outcome labels — positive, negative, terminated, or approved, from hundreds of thousands of trial reports and publications. It's like creating the "ImageNet" for trial outcomes, a data backbone that allows models like SPOT to train on far richer and more diverse examples.
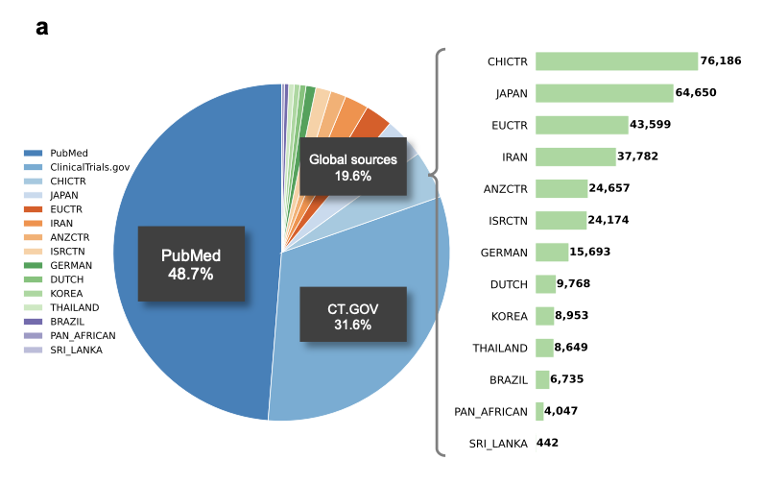
But if outcomes are the "answers," what about the "questions"? To make accurate predictions, models need detailed inputs about each trial, what disease, which population, what endpoints, what competing studies exist. That's where TrialPanorama [4] comes in. It aggregates over 1.6 million clinical trials from fifteen global registries, linking them with DrugBank, MedDRA, and PubMed. Think of it as a panoramic map of global clinical research, capturing every piece of the puzzle: designs, drugs, biomarkers, and outcomes. On top of that, it defines benchmark tasks like arm design, eligibility criteria, and trial completion prediction, helping researchers systematically test and improve AI models for trials.
The Future: Agentic AI Systems
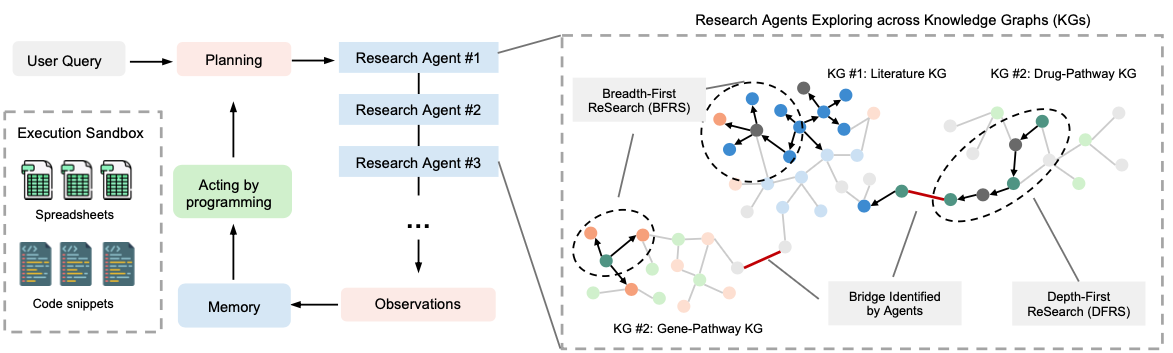
So, where does this all lead? We're moving from predictive models to agentic AI systems: agents that can reason about trial outcomes the way humans do, but at machine speed and scale. Because in real life, evaluating whether a trial will "succeed" is not just about the protocol. It involves checking literature to justify the target mechanism, monitoring competing trials, benchmarking efficacy against market comparators, and even estimating the economic return if approved.
At Keiji AI, we're building prototypes of these multi-agent systems. Imagine an AI analyst team where one agent scans new literature, another monitors live trial databases, another cross-references biomarkers with patient registries: all feeding evidence to a reasoning core that synthesizes a probability of success. It's not magic, but it's getting close to the scientific assistant every clinical developer wishes they had.
Predicting trial outcomes will never be perfectly deterministic: after all, biology loves to surprise us. But with data-rich foundations like CTO and TrialPanorama and adaptive models like HINT and SPOT, AI can make those surprises far less costly. We'll share more soon about how our trial intelligence agents reason, argue, and update predictions in real time.
References
[1] Fu, T., Huang, K., Xiao, C., Glass, L. M., & Sun, J. (2022). HINT: Hierarchical Interaction Network for Clinical Trial Outcome Prediction. Patterns, 3(4). https://doi.org/10.1016/j.patter.2022.100445
[2] Wang, Z., Xiao, C., & Sun, J. (2023). SPOT: Sequential Predictive Modeling of Clinical Trial Outcome with Meta-Learning. ACM BCB. https://doi.org/10.1145/3584371.3613001
[3] Gao, C., Pradeepkumar, J., Das, T., Thati, S., & Sun, J. (2024). Automatically Labeling Clinical Trial Outcomes: A Large-Scale Benchmark for Drug Development. arXiv preprint arXiv:2406.10292. https://arxiv.org/pdf/2406.10292
[4] Wang, Z., et al. (2025). TrialPanorama: Database and Benchmark for Systematic Review and Design of Clinical Trials. arXiv preprint arXiv:2505.16097. https://arxiv.org/pdf/2505.16097